Database migrations: from draft to production-ready

Torben
•
17.01.2024
The first steps
At the very start of the implementation phase we came together to design our database schema. We ended up with two distinct models: User and Transcript. The User model covers essential authentication data such as an unique email and user ID, with each user having uploaded transcripts linked to their account. During the planning phase for the transcript model, we conducted a brainstorming session to map out the core attributes for user-uploaded audio data and transcript downloads. The Transcript model includes attributes like filename for audio file reference in S3 storage, audioUrl for the S3 storage link during file processing, and a status field that updates at each step in the transcription pipeline (Pending, Processing, Failed, Success). To distinguish between transcript formats (docx, srt, txt) when presenting download options in the frontend, individual fields are designated for each. To establish the User Transcript relation, the user field is included.
model User {
id Int @id @default(autoincrement())
email String @unique
name String
Transcript Transcript[]
}
model Transcript {
id Int @id @default(autoincrement())
filename String
audioUrl String?
status TranscriptStatus @default(PENDING)
transcriptUrlDoxc String?
transcriptUrlTxt String?
transcriptUrlSrt String?
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
userId Int
user User @relation(fields: [userId], references: [id])
}
enum TranscriptStatus {
PENDING
PROCESSING
FAILED
SUCCESS
}Iterations
Upon realizing that the original draft will need further refinement, we started making adjustments during development whenever they were needed, taking advantage of the flexibility that this phase offers. To enhance the product before going to production, our first modification involved adding a preview attribute to the Transcript model.
model Transcript {
...
preview String?
...
}The purpose of this preview field is to store the initial segment of the transcript, offering a preview in the dashboard.
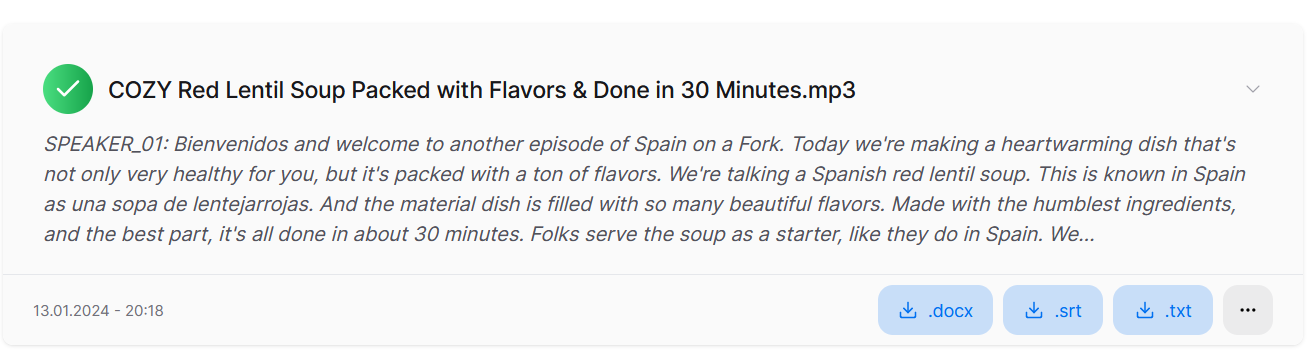
This preview aims to improve the user experience by providing users with a clear understanding of the audio file and its corresponding transcript directly from the dashboard. It also supports to get first insights on whether the transcript is properly processed.
In our second iteration, an adjustment was made to align our Prisma schema with the specifications of Supabase. Recognizing that Supabase operates with Strings rather than Integers in their authentication table, we modified our schema accordingly.
model User {
id String @id @unique
...
}
model Transcript {
id String @id @default(cuid())
...
userId String
user User @relation(fields: [userId], references: [id])
}Specifically, we changed the user id field from an integer to a string to ensure seamless compatibility between Prisma and Supabase. This change was made to maintain their consistency.
In our third iteration, we decided to make adjustments in the handling of file names for uploaded audio files, specifically in relation to what is displayed to the user. Previously, we presented the file name as stored in the S3 object storage directly to the user. However, we already had the concern given that users can upload audio files with any names, such as "test.wav" or "recording.mp3", therefore potential clashes in S3 storage needed to be addressed. To ensure the proper file management and access, we decided to extend file names in attempts to prevent issues by appending a random UUID (Universally Unique Identifier) to the file name.
For instance, a "test.wav" file would be transformed into "test-d4a46644-3c19-41bc-88d8-e6b837e97d13.wav." This adjustment allows us to avoid conflicts in S3 storage, ensuring that multiple files with the same original name can be managed seamlessly.
To maintain user-friendly information in the dashboard, we introduced the originalFilename attribute to the Transcript model. This attribute stores the initial filename provided by the user ("test.wav" as per the example), enabling clear display to the user.
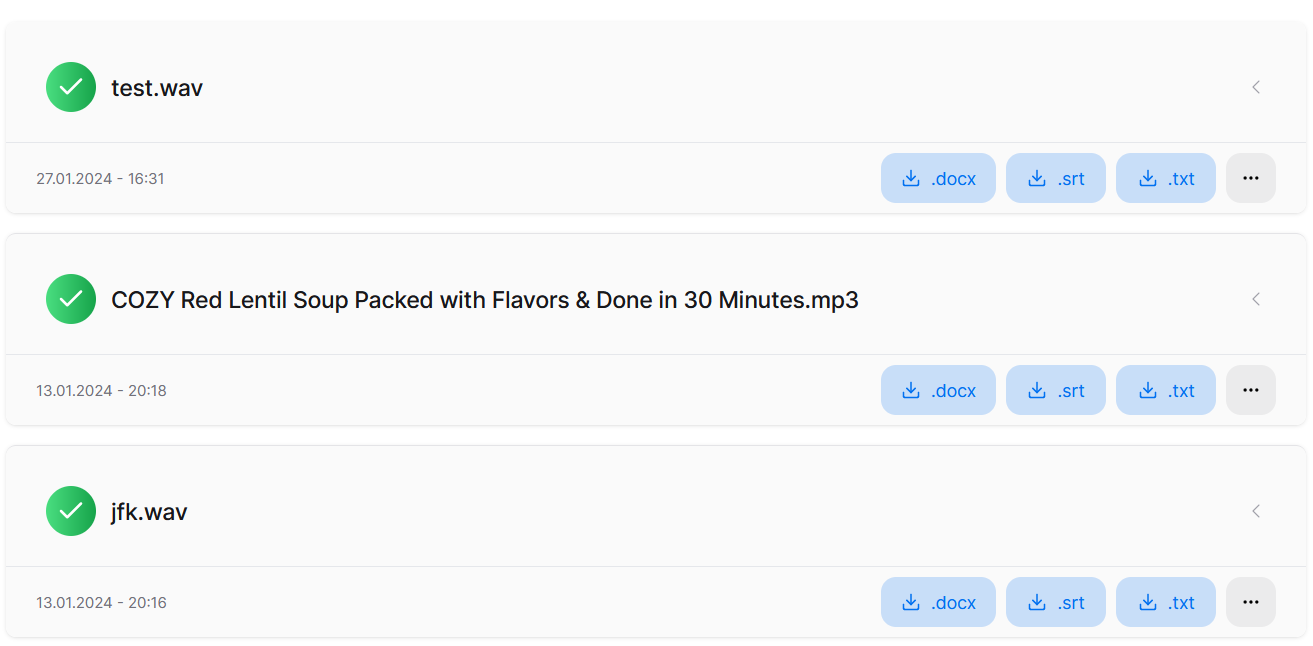
The extended filename with the appended UUID is used internally in our backend for the audio file processing pipeline. The modified Prisma schema snippet reflecting these changes is as follows:
model Transcript {
...
filename String
originalFilename String
...
}A fourth improvement was made in response to the decision on how to handle the final transcripts. Initially, we planned to store the transcript file links from S3 in the Supabase database, providing these links directly to users in the frontend. However, AWS makes this intention challenging as S3 presigned URLs are temporary and valid for only up to seven days. We would have needed some logic in place to ensure the URLs are always up to date and active.
To address this, we opted for an alternative solution. We implemented buttons for each transcript download option (docx, srt, and txt) in the frontend. Upon each button click, we dynamically generate a presigned URL for accessing the file in our S3 object storage, valid for a short period of 5 minutes. This approach eliminates the need to store the links in the database, enhancing security by granting access to the files only when needed. As result of this change, we were able to remove the corresponding fields for transcript links from the Transcript model: transcriptUrlDoxc, transcriptUrlTxt and transcriptUrlSrt were no longer part of it.
As per latest iteration, we refined the file name handling. The following code snippet showcases the separation of file name and extension, its length reduction in case users uploaded a very long filename, and the creation of the new name with a UUID and original extension used for the transcription process running in the backend. A process, that is needed in many places of our application.
const fileName = input.fileName;
// separate filename from file extension
const indexOfLastDot = fileName.lastIndexOf(".");
let baseFileName = fileName.slice(0, indexOfLastDot);
const fileExtension = fileName.slice(indexOfLastDot);
// reduce length of filename to 200 characters
if (baseFileName.length > 200) {
baseFileName = baseFileName.substring(0, 200);
}
// create file name with a random uuid and the file extension
const fileNameWithUuid = `${baseFileName}-${randomUUID()}`;We run through several lines of code to have the name in the desired format. To prevent potential errors in file name manipulation during the pipeline and to avoid repeating those steps whenever needed, we introduced three distinct name variations stored in the model to ease the process.
The following table shows an example of a database entry:
| fileNameWithExt | fileName | fileExtension | displayFilename |
|---|---|---|---|
| test-a7f24ae0-9512-4a03-agbf-db5c7c9a81fe.mp3 | test-a7f24ae0-9512-4a03-agbf-db5c7c9a81fe | .mp3 | test.mp3 |
The fileName is utilized for generating comfortable download options for transcripts, representing the actual file name used for storage in S3. For instance, a docx transcript for "test.wav" is stored as "test.docx". The fileExtension is stored independently to ensure accurate processing of the file during transcription and merging it. The fileNameWithExt serves as the key for accessing the file in S3, streamlining the retrieval process. Lastly, the displayFilename (formerly originalFilename) retains its role in the dashboard for user-friendly display, now renamed for improved clarity. This approach enhances consistency and reduces the risk of errors in file manipulation throughout all processes.
Final schema
model User {
id String @id @unique
email String @unique
name String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
Transcript Transcript[]
}
model Transcript {
id String @id @default(cuid())
fileName String
fileExtension String
fileNameWithExt String
displayFilename String
preview String?
status TranscriptStatus @default(PENDING)
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
userId String
user User @relation(fields: [userId], references: [id])
}
enum TranscriptStatus {
PENDING
PROCESSING
FAILED
SUCCESS
}Conclusion
To sum up, while the schema might not have changed drastically, the adjustments were necessary and improved Ton-Texter. It enables a user-friendly database structure, facilitates our backend processes and covers all given aspects of the application.