Reworking the S3 file upload

Torben
•
20.01.2024
In the audio transcription workflow, we rely on an S3 bucket to store the audio files uploaded by users. These files persist in the bucket until processing is complete, at which point they are promptly removed. Given that this is our first experience working with S3, we encountered unforeseen challenges that arose precisely when we were least expecting them.
Initial integration
In the beginnings of the implementation phase, we implemented the S3 upload feature. Our exploration of the AWS documentation led us to having a quick and simple understanding of how to configure the S3 infrastructure to have it working with our Next.js application, as detailed in our previous blog post titled Integrating S3 in our Next-App.
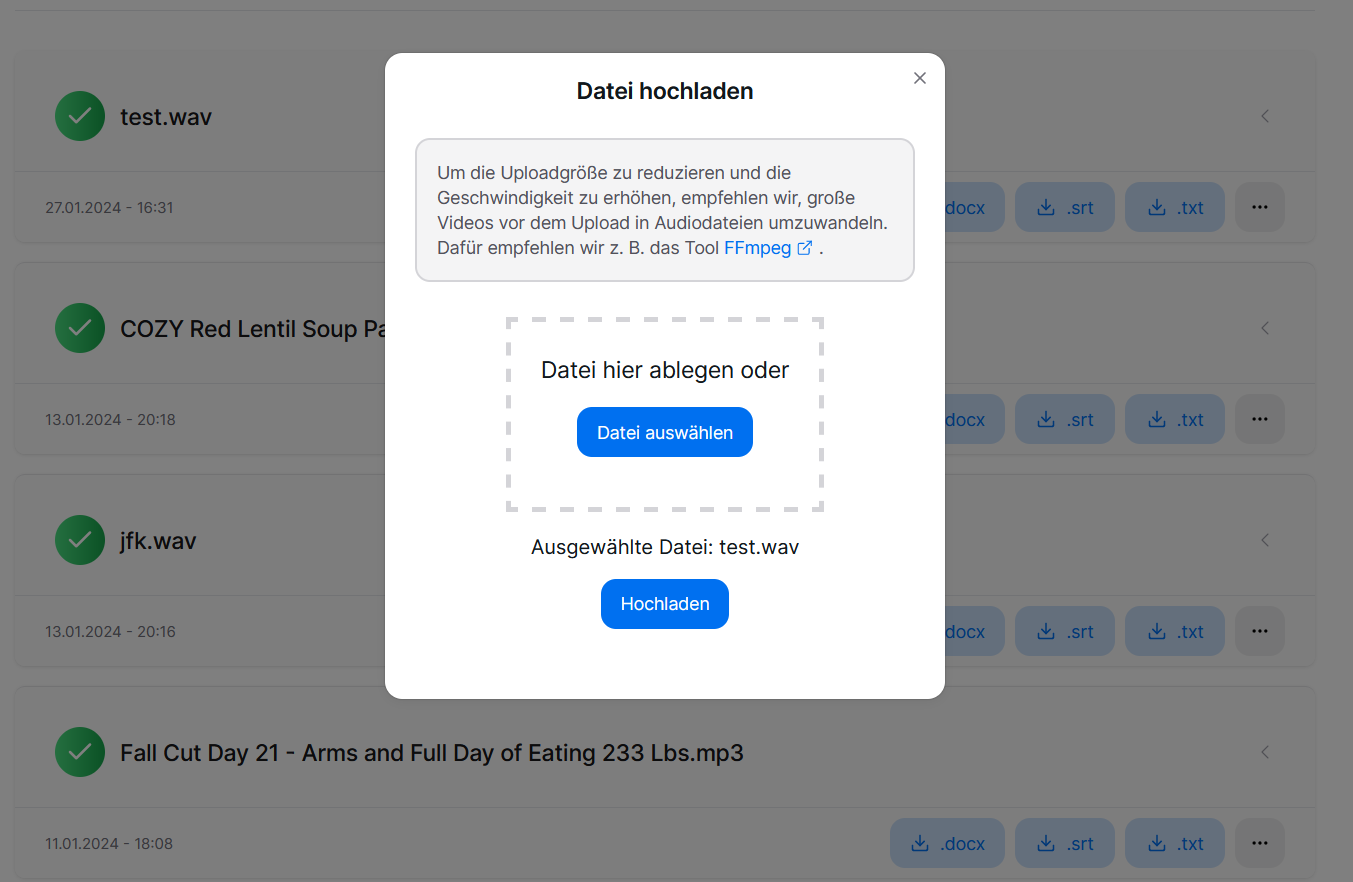
The file upload process followed a rather straightforward sequence. Users could either drag and drop or use the file explorer to select an audio file for upload. To prevent unneeded files in the storage, especially since it is an audio-focused web app and prevent processing errors, only audio files are permitted for upload. This restriction is essential to avoid unnecessary complications and potential overuse of S3 storage. Upon clicking the "Upload" button in the file upload modal dialog, the selected file was transmitted to the specified API backend. The following code snippet demonstrates the initial flow in the client:
const handleUpload = async () => {
if (!file) return;
setUploading(true);
try {
const formData = new FormData();
formData.append("file", file);
formData.append("userId", userId);
const response = await fetch("/api/s3/uploadFile", {
method: "POST",
body: formData,
});
if (response.ok) {
setFile(null);
setUploadSuccess(true);
setUploadError(false);
} else {
throw new Error("Failed to upload file");
}
} catch (error) {
setUploadError(true);
setUploadSuccess(false);
} finally {
setUploading(false);
}
};This function is responsible for uploading the file to the backend to have it processed safely, ensuring data integrity, and updating the application state accordingly. The decision behind managing the file upload on the backend was to be safe against the exposure of S3 credentials, ensuring the security of our application while using the AWS SDK to interact with S3.
The AWS SDK is a rather convenient tool for interacting with our S3 bucket. Its structure allows for straightforward access to essential operations through the provided commands. For instance, the PutObject command provided a direct way of uploading a file to the specified S3 bucket, which streamlined our interactions with S3.
export async function POST(req: NextRequest) {
try {
...
if (!file || !userId) {
return NextResponse.json({ success: false });
}
// Create S3 client
const client = new S3Client({
region: process.env.S3_REGION!,
credentials: {
accessKeyId: process.env.S3_ACCESS_KEY_ID!,
secretAccessKey: process.env.S3_SECRET_ACCESS_KEY!,
},
});
...
const Body = (await file.arrayBuffer()) as Buffer;
// Upload file to S3
const command = new PutObjectCommand({
Bucket: process.env.S3_BUCKET!,
Key: fileName,
Body,
});
const response = await client.send(command);
...
} catch (error) {
return NextResponse.json({ success: false, error });
}
}In the endpoint, a new S3 client session is initialized using the access key ID and secret access key generated by IAM. This approach ensures security, as performing this operation on the client side would allow each visitor to inspect the page's code and potentially abuse the credentials.
The upload process itself is straightforward, as by utilizing PutObjectCommand. This command requires specifying the target bucket, the key (representing the file's name), and providing the file to be uploaded. If the upload was successful, an database entry for the file would be created to have it tracked and the AWS pipeline starts running the transcription process.
Reworking the implementation
The decision to rework the file upload process resulted by several considerations. As explained in the previous chapter, initially, the file upload was managed within an API endpoint to secure the the S3 credentials. However, limitations on serverless function execution time (capped at 10 seconds) and storage capacity (limited to 100GB-hours) in the Vercel free tier helped us to imagine upcoming problems in the future. As the potential for large file uploads or an increase in user numbers could surpass these limitations, an alternative solution was needed.
While using AWS SDK's Get and Put commands offered a direct interaction with the file storage, it wasn't suitable for frontend operations. This led to the integration of AWS S3 presigned URLs, which are time-limited and offer a more scalable approach for client-side interactions.
The rework aimed to change the entire S3 file upload process to be done on the client side. This involved integrating tRPC type-safe routes that were previously missing. The original endpoint for file upload was replaced with a new one dedicated to generating a presigned AWS S3 URL.
const { mutate: createUploadUrl } = trpc.createUploadUrl.useMutation({
onSuccess: async ({ url, fileName, fileNameWithUuid, fileExtension }) => {
if (!file) return;
const uploadResponse = await uploadToS3(url, file);
if (!uploadResponse.ok) throw new Error("Failed to upload file to s3");
createTranscription({
fileName,
fileNameWithUuid,
fileExtension,
});
},
onError: () => {
setUploadError(true);
setUploadSuccess(false);
setUploading(false);
},
});As showcased in the upper code snippet, the presigned URL is now used on the client for uploading the file directly to S3 using the uploadToS3 function without having any S3 credentials exposed.
async function uploadToS3(url: string, file: File) {
"use client";
const uploadResponse = await fetch(url, {
method: "PUT",
body: file,
});
return uploadResponse;
}In case of a successful file upload, the application reverts to the same flow as before the rework. This involves adding an entry to the Supabase database and notifying the user about the successful upload. In case all operations proceeded successfully, the transcription pipeline is then notified to start the transcription process.
Learnings
If we had dedicated more time to explore the S3 documentation and considered our cloud setup more, the need for a rework could have been avoided. Unfortunately, details are often scattered in different documents and pages, particularly in the AWS documentation. It's manageable if you know exactly what you're searching for, but relying solely on given examples without grasping the bigger picture can easily lead to complications and problems when considering the whole project context. This was evident in our experience with S3 and Vercel in this project. Although setting it up and using it is straightforward, understanding its full usage specifications is crucial for taking advantage of its capabilities effectively in connection with Vercel as host for the actual web application. We've learned from these errors and will keep them in mind should we encounter S3 again in the future, which is undoubtedly inevitable.