How we built our own 'serverless' GPU cloud infrastructure

Niko
•
06.02.2024
One of the key challenges of the implementation of Ton-Texter was to find a cost-effective solution to run the transcription in the cloud. The underlying machine learning models of our transcription service, Whisper and Pyannote both run significantly faster on a GPU compared to them running on a CPU. The following chart shows a comparison of Whispers inference time on both a CPU (Intel i5 11300H) and a GPU (NVIDIA T4):
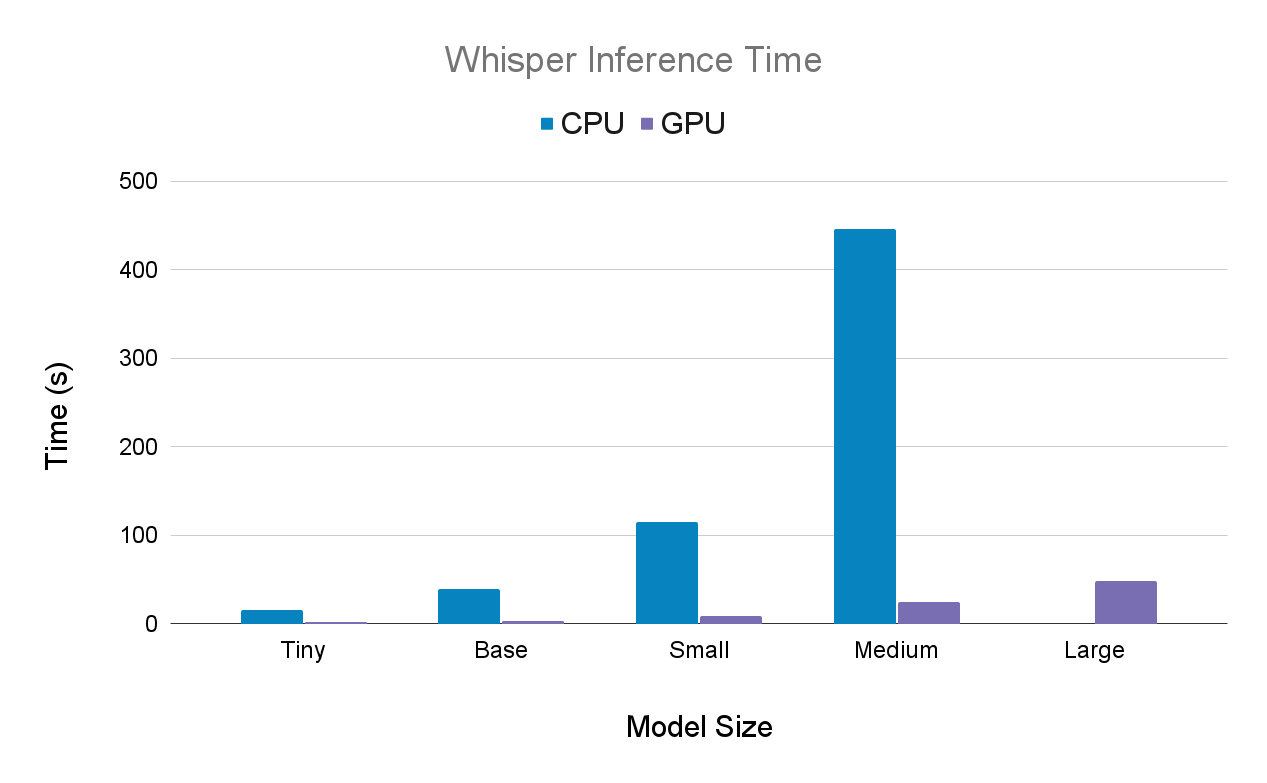
Because of the drastic performance difference the only viable solution is to deploy the transcription on GPU accelerated infrastructure. To ensure that our solution is cost-effective traditional approaches like using EC2 Instances seemed far fetched as we would have to pay for them continuously even if there are no transcriptions running. That would quickly cost us dearly, so we started to look for serverless solutions as we wanted to solely pay for the runtime we actually need.
Continously running the cheapest GPU accelerated EC2 would result in costs of 387$ a month and 4607$ a year, independent of our actual demand.
Serverless CPU-based Lambda functions have been known for a long time now, but unfortunately there are little to no serverless GPU offerings on the market. We found a few new serverless GPU inference platforms that provide GPU Computing on demand, such as Banana.dev or Runpod.io, but unfortunately we discovered several problems with these offerings. With Runpod.io, if the number of machines is set to 0, the API will not work. If it is set to 1, we do have to pay for the continuous usage of one machine even though we do only need it on demand. This would not resolve our initial problem.
Other platforms are limited to templates of popular models or are restricted to uploads in a specific format, therefore limiting the use cases of the provided infrastructure. It would not be possible to deploy our entire python application with its different components, speaker diarization, transcription, transcript file creation to a single instance thus requiring multiple implementations of the individual components. Each instance would have a start up time that slows down the process and depending on the platform is also charged. Therefore none of the compared serverless GPU platforms provide the required infrastructure for our project.
Building our own on-demand EC2 solution
As none of the current serverless GPU offerings on the market satisfies our requirements we implemented our own solution based upon the three AWS Components: API Gateway, Lambda and EC2. Instead of running the EC2 continuously, we built a solution around it to ensure that it is only running when there are tasks in our transcription queue. Whenever a new file to transcribe is uploaded our front-end calls an API Gateway endpoint that triggers a Lambda function that, if not already running launches our EC2 instance. After transcribing the tasks in the queue the EC2 shuts itself down again.
API Gateway
We setup the AWS API Gateway endpoint with terraform. If you are interested in the complete setup consider checking out our Cloud-Transcription-Service Repository. The following excerpt shows how to connect the endpoint with the lambda function:
resource "aws_api_gateway_integration" "lambda_integration" {
rest_api_id = aws_api_gateway_rest_api.transcription_gateway.id
resource_id = aws_api_gateway_resource.root.id
http_method = aws_api_gateway_method.proxy.http_method
integration_http_method = "POST"
type = "AWS_PROXY"
uri = aws_lambda_function.start_lambda.invoke_arn
}Note that the integration_http_method must be set to POST, even though our endpoints method is GET, as it is the method that API Gateway and Lambda communicate with each other.
After deploying, this is how the setup looks like in the AWS Dashboard:
Lambda
When the lambda function gets invoked it uses the boto3 library to check whether the EC2 instance is already running and, if not, to start it. The following Python code snippet shows the status check of the instance and the instantiation, when necessary:
ec2 = boto3.client('ec2')
# Check the current state of the instance
instance = ec2.describe_instances(InstanceIds=[instance_id])['Reservations'][0]['Instances'][0]
current_state = instance['State']['Name']
response_msg = ""
# Start or stop the instance based on its current state
if current_state == 'stopped':
ec2.start_instances(InstanceIds=[instance_id])
response_msg = f"Instance started: {instance_id}"
elif current_state == 'running':
response_msg = f"Instance already running: {instance_id}"
...The endpoint, respectively the lambda execution is protected with a secret key. The following excerpt shows the examination of the key:
if provided_key != transcription_key:
response = "Incorrect API Key provided"
return { 'statusCode' : 401, 'body' : json.dumps(response)}That way we can ensure that our EC2 is not started illegitimately.
EC2
In our blog post Using CUDA with an AMI on AWS EC2 we have already described how we setup our EC2 to use GPU acceleration. But there are some further steps required to continuously deploy the instance with all the required libraries and our Python application.
Via the user_data we do provide a setup script to the application that is run on its initialization. The script is referenced in terraform as follows:
user_data = "${file('init_transcript.sh')}" The script clones the Github Repository of our Python transcription application and proceeds to install all the necessary libraries and requirements. Subsequently it sets up a Cronjob that launches a startup.sh script every time the machine is booting. The following excerpt shows the autostart configuration.
# Autostart
sudo cat >/etc/cron.d/startup_script <<EOL
@reboot root /home/ubuntu/startup.sh
EOL
sudo cat /etc/cron.d/startup_scriptThe startup.sh file is defined in the following way:
# Configure Startup Script
sudo cat >/home/ubuntu/startup.sh <<EOL
#!/bin/bash
log_file="/var/log/startup.log"
target_dir="/home/ubuntu/Transcription-Application"
exec > >(tee -a "\$log_file") 2>&1
cd "\$target_dir"
sudo git pull
sudo python3 main.py
sudo poweroff
EOL
sudo cat /home/ubuntu/startup.sh
# Enable Startup Script
sudo chmod +x /home/ubuntu/startup.sh
We do setup a log file so that we can have a look into whats going wrong if any errors occur. Afterwards the script pulls from the Github Repository of the transcription application to ensure that the application is up to date. This is a very convenient workflow, as the EC2 does not need to be redeployed when improvements are made to the application. After updating the application, the script executes the application. When the application transcribed all pending tasks the machine shuts itself off with the command sudo poweroff. This is how we can ensure that the EC2 is only running as long as it needs to be.
Conclusion
To get an understanding of how this solution integrates with our other infrastructure we are going to have a look at an architecture diagram of Ton-Texter. After implementing this solution the architecture of Ton-Texter looks like this:

As you can see in the diagram above the Transcription Service is triggered from our NEXT.js application via an API call to API Gateway. This invokes, as explained earlier, a Lambda function that launches our EC2 instance, that executes our Python application for the transcription which communicates via an API with our back-end.
Overall, this proved to be a very cost-effective solution as we do only get billed for the minutes the machine is running. Together with improving the speed of our transcription this led to very competitive running costs.
The cost of transcription with Ton-Texter are as low as 0.08$ per hour of audio
You can read more about the cost evaluation in our blog article: Is Ton-Texter actually competetive?. If you're interested in how the transcription on the EC2 is performed, consider reading our blog post The backbone of Ton-Texter: Transcription based on OpenAI Whisper / Pyannote.