The backbone of Ton-Texter: Transcription based on OpenAI Whisper / Pyannote

Niko
•
29.01.2024
The core functionality of Ton-Texter is to transcribe audio and video files. Additionally we perform a speaker diarization. Ton-Texter aims to provide state of the art transcription results. Stick to this blog post to get more information on how we built our transcription pipeline.
Major performance improvements in text to speech: OpenAI Whisper
Through the implementation of unsupervised pre-training techniques speech recognition improved greatly in recent years. This allowed the usage of unlabeled speech datasets increasing the hours of speech a model was trained on from a typical 1000 hours, when using a supervised dataset, to now up to 1.000.000 hours. One popular example is OpenAIs Whisper.
Whisper can perform multilingual speech recognition with a performance that is close to human transcription, outperforming its competitors. Depending on the dataset it is tested with Whisper can achieve a Word Error Rate of less than 5% in german.
The following chart shows a comparison of Whisper, its competitors and human transcription based on the Kincaid46 dataset:
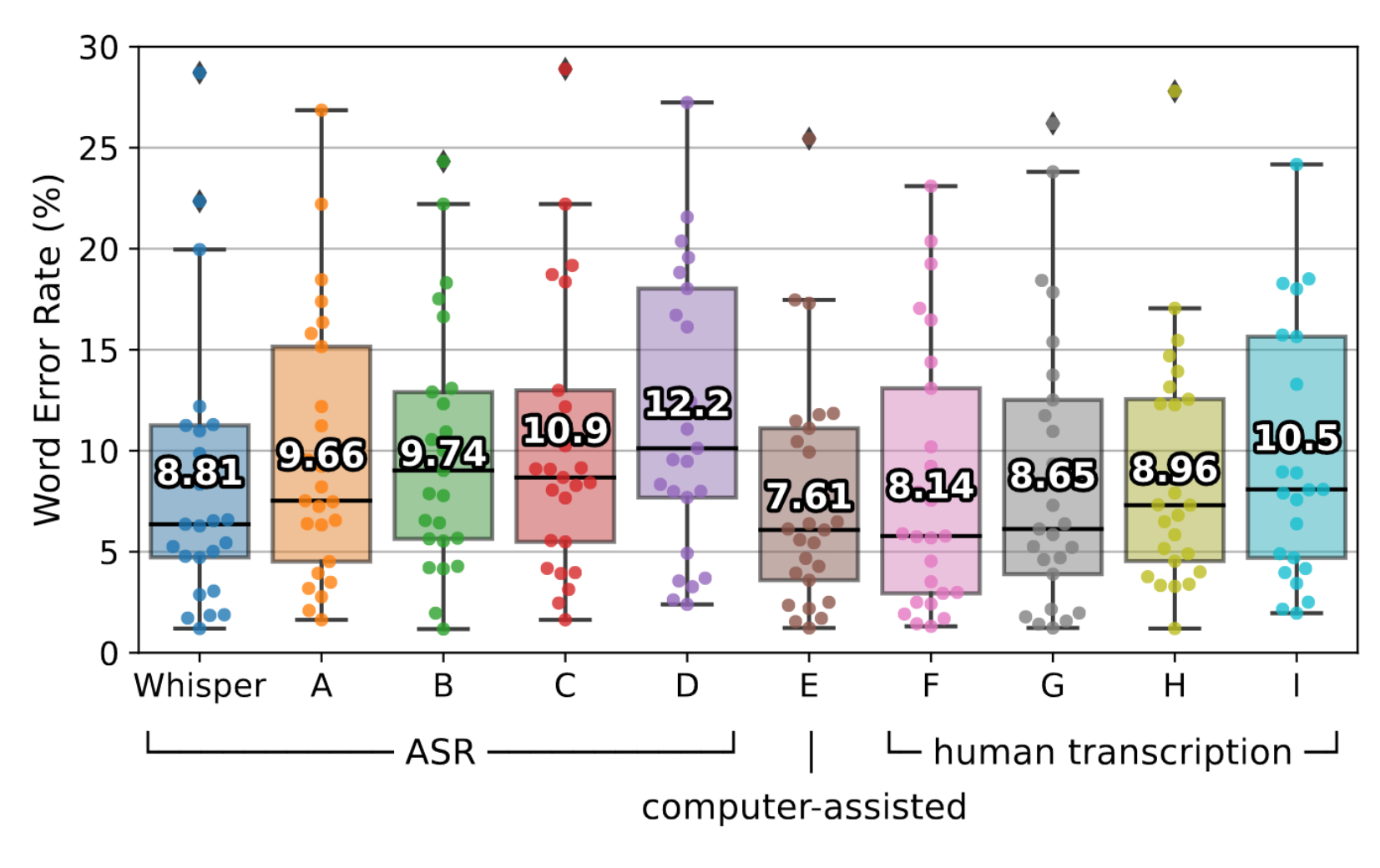
As seen in the plot above, whisper occasionally outperforms even human based transcription services. This is why we decided to built our application with Whisper.
Running Whisper with Python
It is very easy to setup Whisper in Python. This is demonstrated in the following code sample taken from Whispers Github page:
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])Selecting the adequate Model Size for Ton-Texter
As already shown in the code snippet above Whisper provides several different model sizes. In the beginning we had chosen to go with the base model, thanks to the implementation of performance improvements we later chose to go with the small model to further improve our transcription.
For a rapid transcription it is recommend to use Whisper with a NVIDIA GPU and CUDA. To see how we have managed to do that, consider reading our blog post on using CUDA with an AMI on AWS EC2.
Why do we use Speaker Diarization?
Identifying the speakers helps us to improve the structure of the provided transcript files and enables support for multi-lingual input files.
Whisper itself is only capable of transcribing a file in one single language. By separating the audio in parts, dependent on its speakers, we can transcribe files with speakers speaking different languages.
For the identification of different speakers we use Pyannote. This pretrained model returns speaker segments with a diarization error of around 10% depending on the test dataset. In comparison to other available speaker diarization models such as Nemo, Pyannote delivers larger segments containing full sentences which is more suitable for our use case.
Implementation of Pyannote
The pretrained Pyannote 3.1 model is available on huggingface. The following code snippet shows the setup of the speaker diarization pipeline in our application.
def speaker_diarization(sourcefile, secret):
# usage of pyannote pretrained model for speaker diarization
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token=secret["HUG_TOKEN"])Ensure that Pyannote runs on CUDA
One thing we want to make sure of initially is to check whether Pyannote can use a CUDA capable GPU or not. This is important because the pipeline is significantly slower on CPU therefore we must make sure that it is running on the GPU.
# check if CUDA capable GPU is available
try:
print("Attempting to use CUDA capable GPU")
pipeline.to(torch.device("cuda"))
except:
print("Using CPU instead")
pipeline.to(torch.device("cpu"))If the console output is "Using CPU instead" we have to investigate the setup of our device, drivers and torch installation.
To setup an EC2 machine with CUDA support consider reading our seperate blog post using CUDA with an AMI on AWS EC2.
Running the Pipeline
After we have made sure that our pipeline is running on our GPU we can start our pipeline as follows:
with ProgressHook() as hook:
diarization = pipeline(sourcefile, hook=hook)With the ProgressHook we can monitor the progress of the pipeline.
Transcribing the individual Speaker Segments
Pyannote returns a list of speaker segments.
Through our thorough testing we analyzed that often times segments of the same speaker follow each other.
To avoid the unnecessary separate transcription of these segments and to reduce the number of overall segments we created a function condenseSpeakers that concatenates segements of the same speaker that follow each other.
For the transcription of the speaker segments we iterate over them, generate a .wav file with FFmpeg and transcribe the individual files with Whisper:
for segment in speaker_segments:
# render a wav for the current segment for the transcription
segmentName = "segment_" + str(segment.in_point) + ".wav"
subprocess.call(['ffmpeg', '-i', filename, '-ss', str(segment.in_point), '-to', str(segment.out_point), segmentName, '-y','-loglevel', "quiet"])
# transcription using OpenAI Whisper
result = model.transcribe(segmentName)In our blog post on improving the performance of our transcription we replace the rendering of separate audio files with FFMPEG with a better performing solution.
Separate segments but same overall timecode?
One major problem that comes with transcribing the speaker segments individually is the loss of an overall unified timecode.
This is very important for the generation of our .docx and .srt file. To understand this problem it might help to look at an example .srt file:
1
00:00:01,503 --> 00:00:25,503
Hallo meine sehr verehrten Damen und Herren, in letzter Zeit bekomme ich hier auch am Vermehrt immer wieder Anfragen für Musikauftritte, beispielsweise sogar in Basel oder auch in Berlin oder auch hier im Umkreis.
2
00:00:31,503 --> 00:00:48,503
Dazu kann ich eigentlich allgemein sagen, ich habe ja derzeit gar keine Lautsprecheranlage, APA-Anlage und das ganze andere Zubehör.
In an .srt file, commonly used for subtitles, there are four parts for each subtitle:
- A numeric counter indicating the number or position of the subtitle.
- Start and end time of the subtitle separated by –> characters
- Subtitle text in one or more lines.
- A blank line indicating the end of the subtitle.
With the current implementation approach each speaker segment would start based of a timecode of 00:00:00,000 again. So our .srt file could look like this:
1
00:00:00,000 --> 00:00:25,503
Hallo meine sehr verehrten Damen und Herren, in letzter Zeit bekomme ich hier auch am Vermehrt immer wieder Anfragen für Musikauftritte, beispielsweise sogar in Basel oder auch in Berlin oder auch hier im Umkreis.
2
00:00:00,000 --> 00:00:13,503
Dazu kann ich eigentlich allgemein sagen, ich habe ja derzeit gar keine Lautsprecheranlage, APA-Anlage und das ganze andere Zubehör.This is obviously a corrupt .srt file. To avoid this problem we have to correct the timecode values of the separate segments based of the time that has already passed since the beginning of the audio file until the beginning of the segment. Therefore we add the segment.in_point to the start timecode as well as the end timecode of the segments, as shown in the code snippet below:
timecode_corrected_segments = []
for s in summarized_segments:
timecode_corrected_segments.append({'id':s['id'],'start':segment.in_point + s['start'], 'end': segment.in_point+s['end'], 'text': s['text']})This resolves the timecode problem that comes with transcribing the speaker segments separately.
Generating transcript files
We use the writer function provided by whisper to generate the .srt file. Our .txt is generated with the basic python write function as you can see in the following code snippet:
with open(txt_path, 'w', encoding='utf-8') as f:
f.write(text)For the generation of our word file we use the python-docx library.
Conclusion
Through the usage of OpenAI Whisper we provide state of the art transcription. With the usage of Pyannote we managed to improve this transcription even further. Although this implementation came with some problems at first that needed to be resolved, it is now a key component of Ton-Texters offering and a unique selling point compared to other solutions that are solely based on Whisper.
Surely the transcription pipeline requires more time now with this additional processing step. But we have found this delay, that is roughly 1-2 minutes for a 1 hour audiofile, to be negligible compared to its benefits.
If you want to know more about our transcription pipeline consider reading our blogposts on the improvement of its performance and the evaluation of the pipelines running cost in comparison to existing solutions such as the Whisper API.