How we improved our transcription performance by over 60%

Niko
•
07.02.2024
In our blog post The backbone of Ton-Texter: Transcription based on OpenAI Whisper / Pyannote we explained how we setup our transcription pipeline initially. In this post we are going to discover how we managed to improve its performance even further.
Speeding up the speaker diarization
When we tried to run the speaker diarization on our EC2 instance initially, we discovered that it took over 3 hours for one hour of audio which was very odd, because it took only about 2 minutes on our local machine. After researching potential problems we discovered that this was due to the EC2s EBS storage. Therefore instead of inputting the file into the speaker diarization pipeline we switched to loading the audio into memory first:
waveform, sample_rate = torchaudio.load(sourcefile)
audio_in_memory = {"waveform": waveform, "sample_rate": sample_rate}
with ProgressHook() as hook:
diarization = pipeline(audio_in_memory, hook=hook)This fixed not only the performace problem on the EC2 but did also improve performance overall. A one hour audio file, that initially took 89 seconds to process, is processed in just 80 seconds now.
By loading the audio into memory first we improved the speaker diarization performance by around 10%
Improving the audio segmentation
Initially we rendered a new audio file for each speaker segment of the original audio with FFmpeg, that was then transcribed with Whisper. Later on we discovered the Python library Pydub which is capable of segmenting audio in memory. The following code snippet shows the audio segmentation with Pydub:
# load audio
audio = AudioSegment.from_file(filename,format="wav")
## convert to expected format
if audio.frame_rate != 16000: # 16 kHz
audio = audio.set_frame_rate(16000)
if audio.sample_width != 2: # int16
audio = audio.set_sample_width(2)
if audio.channels != 1: # mono
audio = audio.set_channels(1)
for segment in speaker_segments:
# Slice Audio with pydup
segment_in = int(segment.in_point*1000)
segment_out = int(segment.out_point*1000)
segmentAudio = audio[segment_in:segment_out]
# transcription using OpenAI Whisper
result = model.transcribe(np.frombuffer(segmentAudio.raw_data, np.int16).flatten().astype(np.float32) / 32768.0)This improved the performance of our pipeline again. We ran several tests with different audio files to reevaluate the results. The following charts shows 4 test runs with 2 audio files.
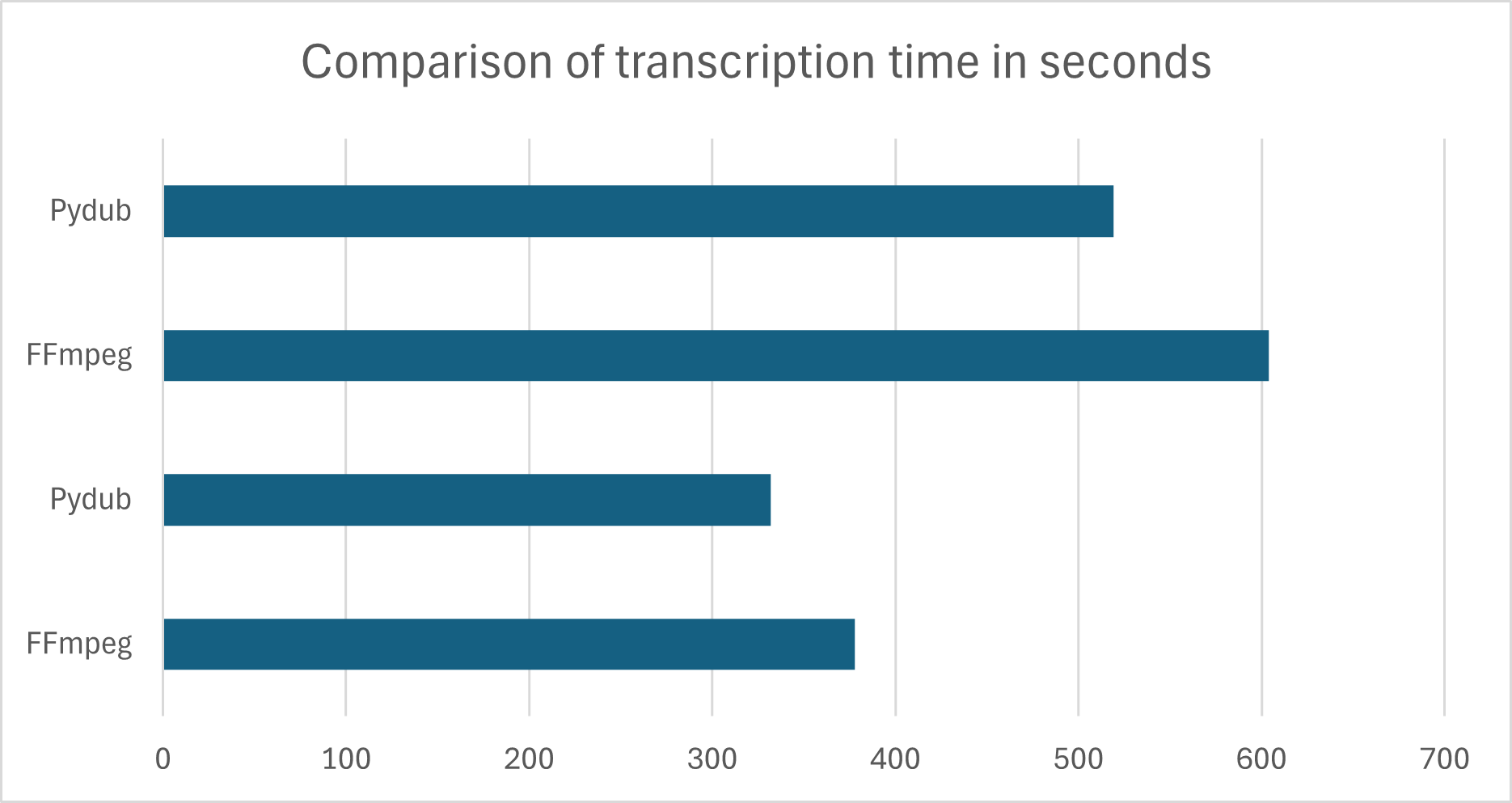
As you can see in the chart we managed to improve the speed of our transcription by another 15%.
Using Faster-Whisper
Faster Whisper is a reimplementation of OpenAI's Whisper model using CTranslate2, which is a fast inference engine for Transformer models. The implementation promises to be around 4 times faster than OpenAis Whisper for the same accuracy. In our testing Faster-Whisper was between 2.5 and 3 times faster then our previous OpenAI Whisper implementation. The following chart shows the time it takes Faster Whisper and OpenAI Whisper to transcribe a 1:30h audio file when using different models:
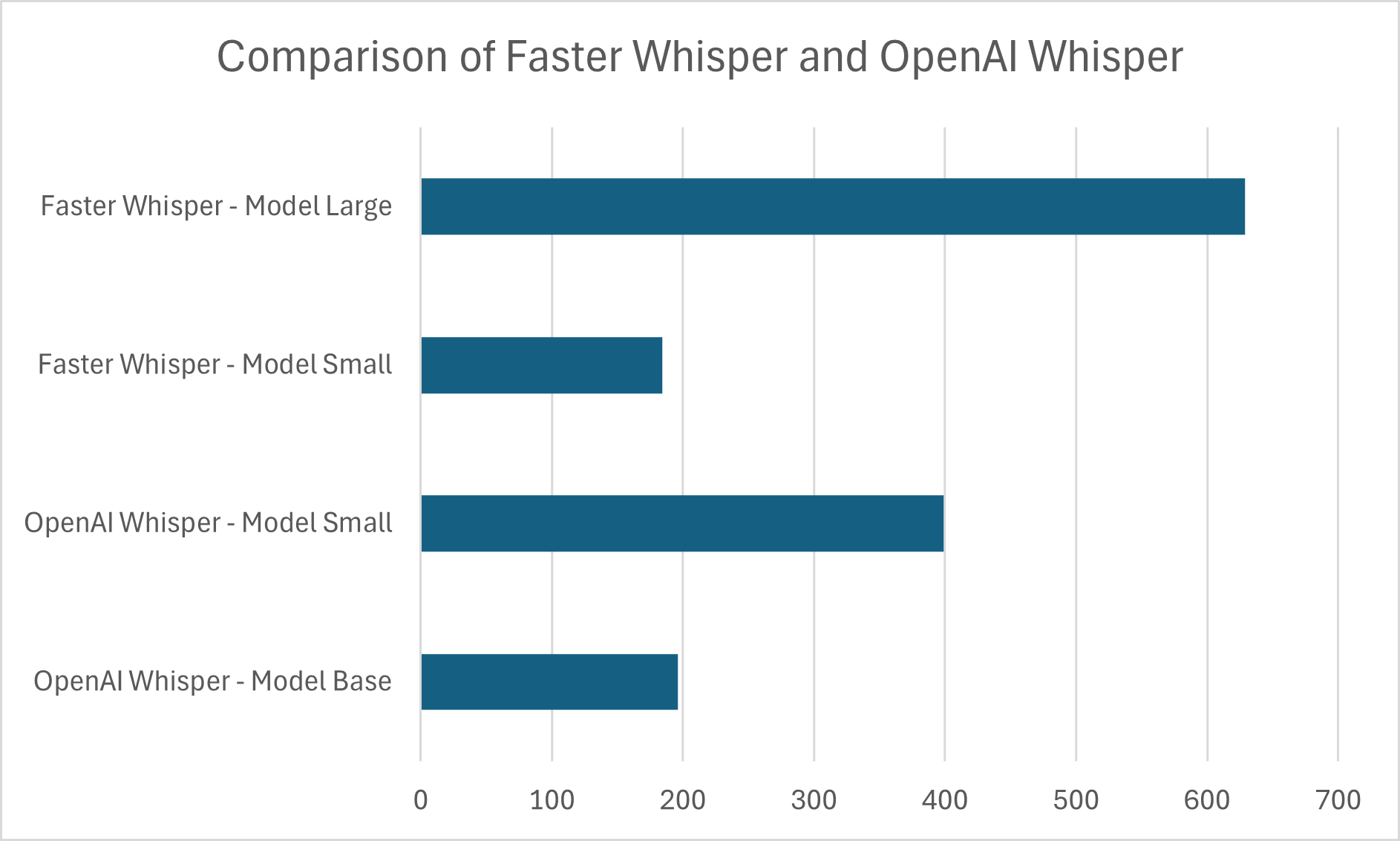
As you can see, Faster Whisper is faster when using the small model then OpenAI Whisper is when using the base model. Until then we had used the base model to power our transcription, but thanks to these significant performance gains we decided to go for the small model to improve its accuracy. Using the large model would still slow down the pipeline significantly even with these performance improvements. We found that the small model offers the best compromise between transcription time and accuracy.
The performance gains of Faster-Whisper enabled us to use the more demanding small model instead of the previously used base model, thus not only improving the transcription speed, but also its accuracy.
Conclusion
Before we implemented these improvements we performed a test run with a sample audio file, measuring the total time it takes from uploading the file all the way to the transcript files being ready to download. We did this test again after implementing all of the mentioned improvements. The following chart shows the result of these test runs:
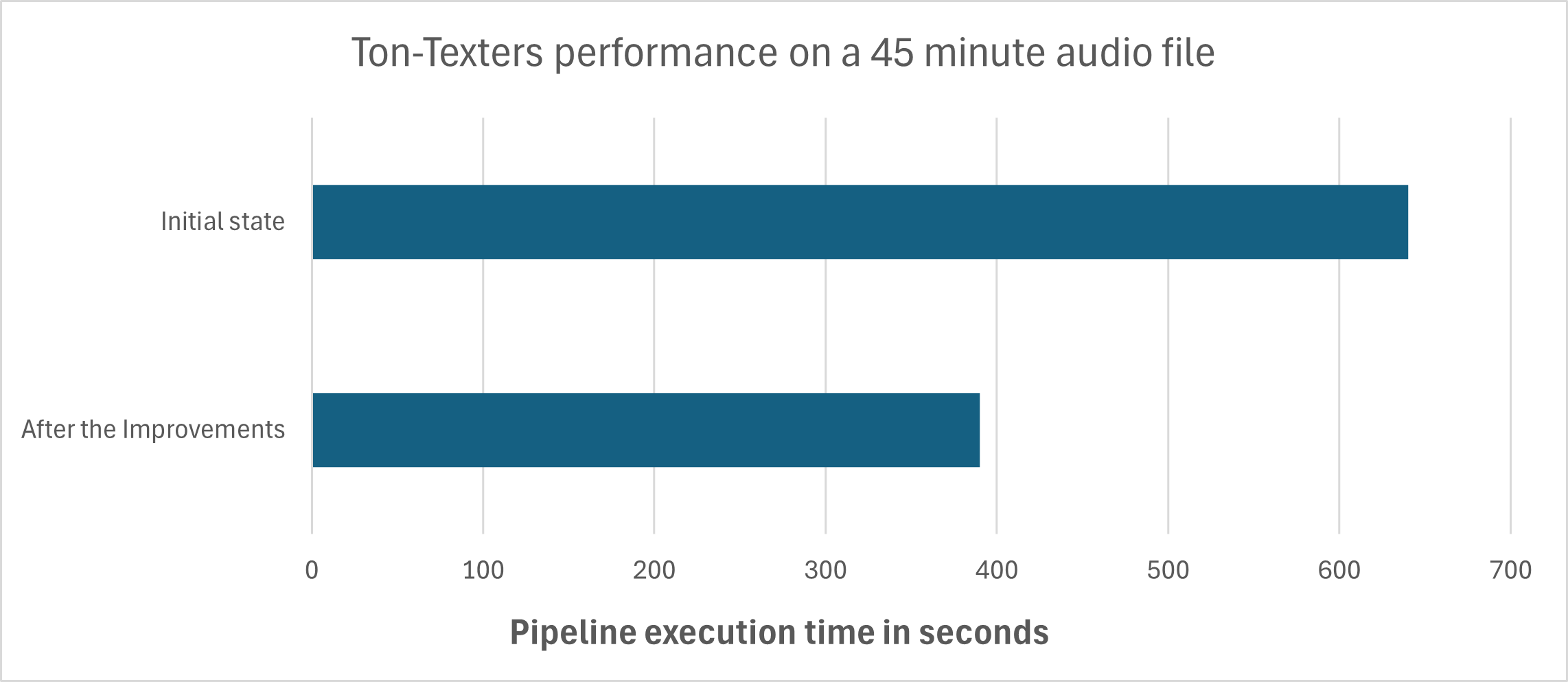
Instead of 10 minutes and 40 seconds, the entire process takes now only 6 minutes and 30 seconds, which is an improvement of more than 64%. If we would be ignoring the startup time and consider that the machine is already running the differences would be even greater.
Keep in mind that we also increased the accuracy along the way. These improvements are the basis for making Ton-Texter a competitve solution. If you want know more about how competitive Ton-Texter actually is, consider reading our blog post Is Ton-Texter really competitive?.